1. Empirical Checkerboard Copula
Oskar Laverny
2025-01-30
Source:vignettes/vignette01_ecb.Rmd
vignette01_ecb.RmdThe empirical checkerboard copula is a model for copula defined by (Cuberos, Masiello, and Maume-Deschamps 2019). It provides a fast and easy way to model a copula in high-dimensional settings (more columns than rows in the dataset). It only requires one parameter, , the so-called checkerboard parameter. In the first section of this vignette, we will set notations and define the model. The second section will discuss and demonstrate the implementation made in the package.
Definition of the empirical checkerboard copula
Suppose that we have a dataset with i.i.d observation of a -dimentional copula (or pseudo-observations). Take the checkerboard parameter to be an integer dividing .
Let’s consider the ensemble of multi-indexes which indexes the boxes :
partitioning the space .
Let now be the dimension-unspecific Lebesgue measure on any power of , that is :
Let furthermore and be respectively the true copula measure of the sample at hand and the classical Deheuvels empirical copula, that is :
- For i.i.d observation of the copula of dimension , let be the marginal ranks for the variable .
We are now ready to define the checkerboard copula, , and the empirical checkerboard copula, , by the following :
Where .
This copula is a special form of patchwork copulas (see Durante) and some results are known about it : it is indeed a copula, it converges to the true copula as the mesh (size of boxes) goes to zero, etc..
This package gives a comprehensive implementation of the empirical counterpart of this copula, which has exactly the same expression except that , the true copula of the sample, is replace by it’s Deheuvel approximation , that is :
A known result is that this is a copula if and only if divides (see cuberos). In this case, some theoretical assymptotics are avaliables.
The next section discuss the implementation.
Implementation
In this package, this empirical checkerboard copula is implemented in
the cbCopula class. This class is a little more general as
it allows for a vector
instead of a single value. Each of the
’s
must divide
for this to be a proper copula. With the same train of thoughts as
before, we have the following expression for this model :
You need to provide a dataset, defining
,
to construct the model. For the matter of this vignette, we will use the
LifeCycleSavings dataset, which has following pairs
dependencies plot :
set.seed(1)
data("LifeCycleSavings")
pseudo_data <- (apply(LifeCycleSavings,2,rank,ties.method="max")/(nrow(LifeCycleSavings)+1))
pairs(pseudo_data,lower.panel=NULL)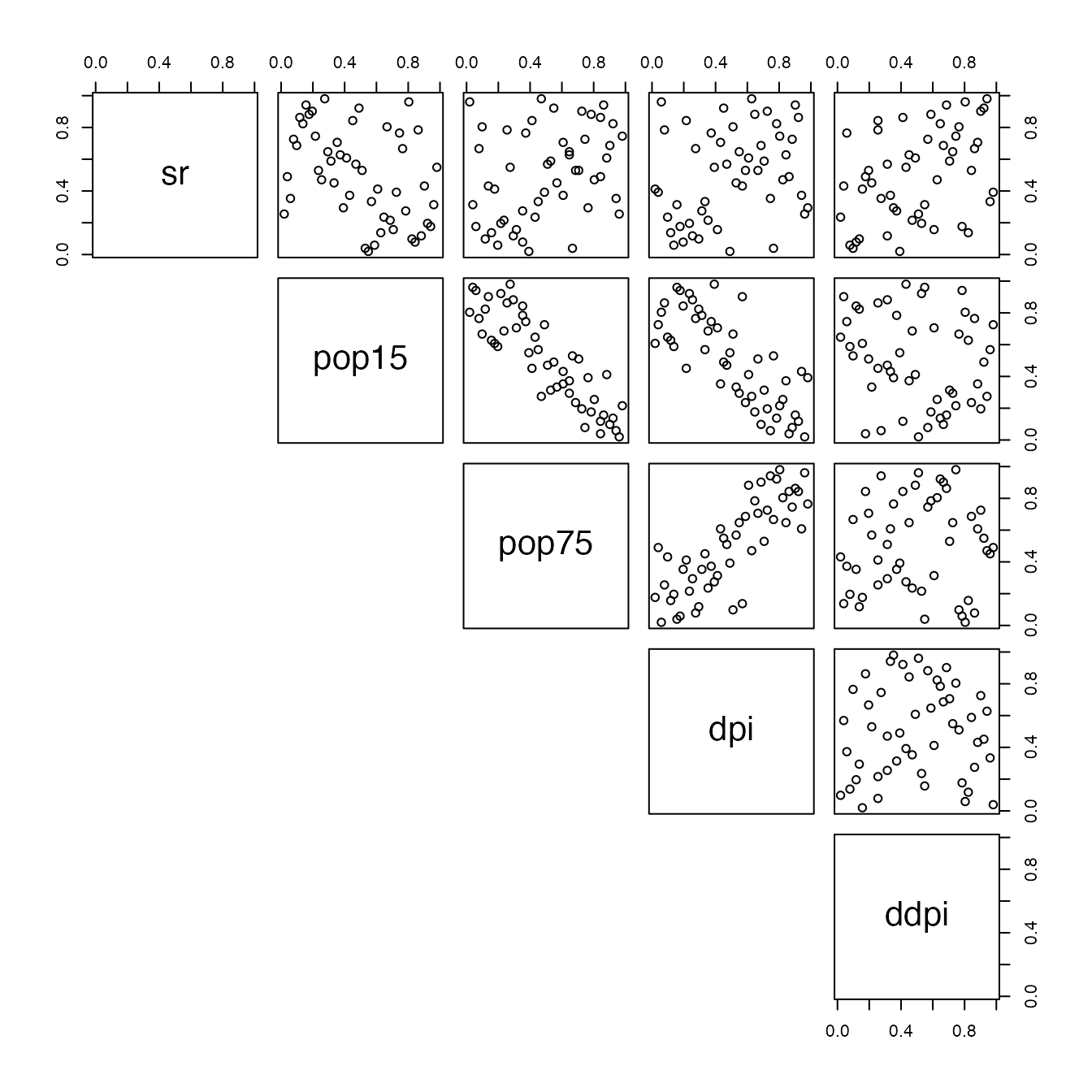
Pairs-plot of original peusdo-observation from the data
You can see that the variable 2 to 4 have dependencies, while the
first and fifth variable seems to be (marginally) independent. The
dataset having
rows, we will pick a value of
dividing
,
e.g
,
and use the function cbCopula to build our copula model.
Since we are already providing the pseudo observations, we will set
pseudo = TRUE. Providing a single value for the
parameter will set all
’s
equal to that value (the default is the proper checkerboard copula).
(cop <- cbCopula(x = pseudo_data,m = 5,pseudo = TRUE))
#> This is a cbCopula , with :
#> dim = 5
#> n = 50
#> m = 5 5 5 5 5
#> The variables names are : sr pop15 pop75 dpi ddpiFor the moment, only some methods exist for this copula. We can
calculate it’s values via the pCopula method, or simulate
from it via the rCopula method. the dCopula
methods gives it’s density. Here is an example of simulation from this
model :
simu <- rCopula(n = 1000,copula = cop)
pairs(rbind(simu,pseudo_data),
col=c(rep("black",nrow(simu)),rep("red",nrow(pseudo_data))),
gap=0,
lower.panel=NULL,cex=0.5)
Pairs-plot of original peusdo-observation from the data (red) with simulated pseudo_observation (black)
About the value of
The value of the checkerboard parameter condition heavily the copula itself. See the vignette about convex mixtures of m-randomized checkerboards for more details.