3. Empirical Checkerboard Copula with known margins
Oskar Laverny
2025-01-30
Source:vignettes/vignette03_ecbkm.Rmd
vignette03_ecbkm.RmdThe empirical checkerboard copula with known margins is a model for copula that uses priori information on a multidimensional margins to condition a checkerboard construction on the rest of the copula. This vignette describes the model in the first section, and then discuss current implementation in the second section
Empirical checkerboard copula with known margins
Preliminary notations
First of all, for a certain dimension of the data at hand and a certain checkerboard parameter , let’s consider the ensemble of multi-indexes which indexes the boxes :
partitioning the space . Denote the set of thoose boxes by . Furthermore, let’s choose dimensions that would be assigned to a known copula, by setting : and let’s define proper projections for the boxes :
such that for all . The tensor product is here understood taking dimensions of in the right order such that dimensions end up in place of dimensions indexed by . Think of dimensions as re-ordered such that .
Let now be the dimension-unspecified Lebesgue measure on any power of , that is :
Let furthermore be a copula measure of dimension , corresponding to the known multivariate margin associated to marginals in . Let also and be dimension-unspecific version of the true copula measure of the sample at hand and (respectively) the classical Deheuvels empirical copula, that is :
- For i.i.d observation of the copula of dimension , let be the marginal ranks for the variable .
We are now ready to define the empirical checkerboard copula with known margins.
Definition, estimation and simulation procedures
The empirical copula with known margins is the copula that correspond to the following simulation procedure.
- Simulate a sample from the known sub-copula , of dimension , through any avaliable method (depends on the known copula model). Let be the (projected) box containing this sample.
- Sample one box
among all boxes with projection
with probability weights :
- if the projected box contains one or more (empirical) data point, that is
- otherwise.
- Simulate uniformly from
This algorithm simulates first the known part of the model (dimensions in ), and then, conditionally, the checkerboard part, ensuring that the known copula is respected. The downside of this behavior is that the checkerboard part may have points outside standard checkerboard boxes, making this part of the copula less sparse than a true checkerboard. But is does become sparser as soon as the data fits the known margins. On the other hand, this algorithm allows for a lot of flexibility, mainly in the following points :
- The “grid” given by can be taken more arbitrarily than boxes of same volume, as soon as it’s a partition of .
- The known copula is not restricted at all and can be chose among all -dimensionnal copulas.
- The estimation of the checkerboard part can be turn into a more flexible patchwork construction, by changing the independence copula for an other one inside the boxes. See Durante2013,Durante2015,Durante2015a
We are now going to define properly the measure associated to this simulation procedure, a.k.a the empirical checkerboard copula with known margins. Let be this measure and let be a random vector drawn from it. Then , following the above procedure, we have :
While the unconditional term is easy to handle since it’s the measure associated with the known copula, , the conditional term can be treated according to the algorithm : it will be inside a box chosen with probability conditional on . We finally get the following definition :
The empirical checkerboard copula with parameter and with set of known margins following the measure is the copula corresponding to the measure given by :
The next section will discuss the current implementation of this copula;
Current implementation
The package implements the empirical checkerboard copula with known
margins through the cbkmCopula class. The constructor of
the class takes several arguments :
-
x, the pseudo_data. -
m=nrow(x), repesenting the checkerboard parameter -
pseudo=FALSE, is the pseudo_data already given in a pseudo_observation form ? -
margins_numbers=NULL, the margins index that are associated to the known copula, formerly noted -
known_cop=NULL, the known copula to be applied to thoose margins : a copula object of right dimension.
for example, let’s take the LifeCycleSavings data :
set.seed(1)
data("LifeCycleSavings")
dataset <- (apply(LifeCycleSavings,2,rank,ties.method="max")/(nrow(LifeCycleSavings)+1))
pairs(dataset,col="2",lower.panel=NULL)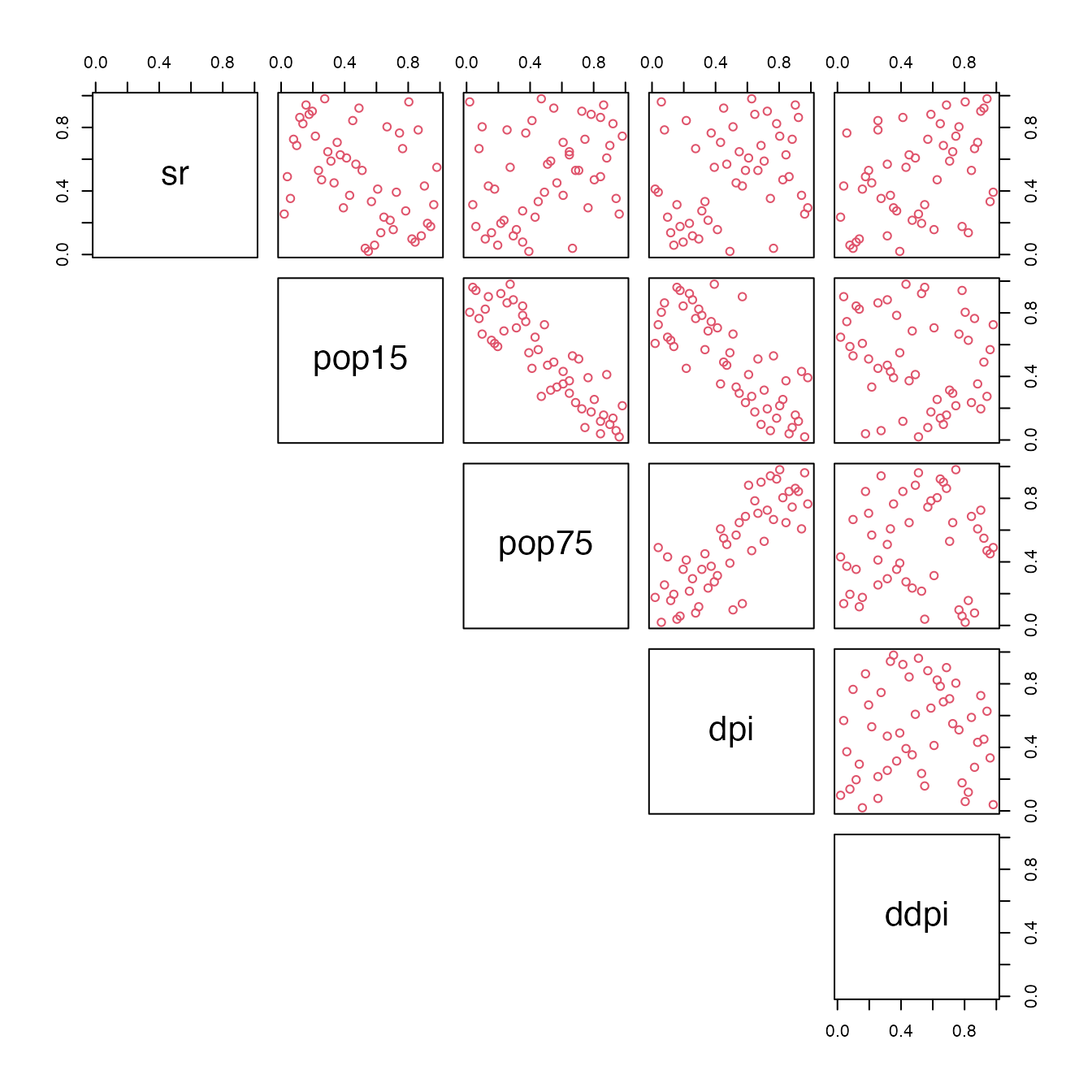
Pairs-plot of original peusdo-observations
let’s now estimate a checkerboard copula on margins 2 and 3 with a precise , and consider it to be known.
Then we can construct the ECBC with this known margin :
(cop <- cbkmCopula(x = dataset,m = 5,pseudo = TRUE,margins_numbers = known_margins,known_cop = known_copula))
#> This is a cbkmCopula , with :
#> dim = 5
#> n = 50
#> m = 5 5 5 5 5
#> The variables names are : sr pop15 pop75 dpi ddpi
#> The variables 2 3 have a known copula given by :
#> This is a cbCopula , with :
#> dim = 2
#> n = 50
#> m = 25 25
#> The variables names are : pop15 pop75We can then simulate from it :
simu <- rCopula(1000,cop)
pairs(rbind(simu,dataset),col=c(rep("black",nrow(simu)),rep("red",nrow(dataset))),gap=0,lower.panel = NULL,cex=0.5)
Pairs-plot of the original data (red) and simulated data from a good model (black)
You can see that the known margins were respected, which is the whole point of this model. Let now see an example with a clearly wrongly-specified copula for the known margins :
bad_known_copula <- cbCopula(x = dataset[,known_margins],m = 2,pseudo = TRUE)
cop <- cbkmCopula(x = dataset,m = 5,pseudo = TRUE,margins_numbers = known_margins,known_cop = bad_known_copula)
simu <- rCopula(1000,cop)
pairs(rbind(simu,dataset),col=c(rep("black",nrow(simu)),rep("red",nrow(dataset))),gap=0,lower.panel = NULL,cex=0.5)
Pairs-plot of the original data (red) and simulated data from a wrong model (black)
This example shows the sensitivity of the estimation on other parts of the model to the good behavior of the prior estimate. The conditioning did suffer for the dependences inside the known multidimensional margin but also for dependencies involving one of the variables from thoose known margins. But the checkerboard construction for the other part of the copula was not harmed.
What now if the 2 parts are clearly independent ?
true_copula1 <- known_copula
true_copula2 <- bad_known_copula
dataset <- cbind(rCopula(1000,true_copula1),rCopula(1000,true_copula2))
colnames(dataset) <- c("u","v","w","x")
pairs(dataset,lower.panel=NULL,cex=0.5)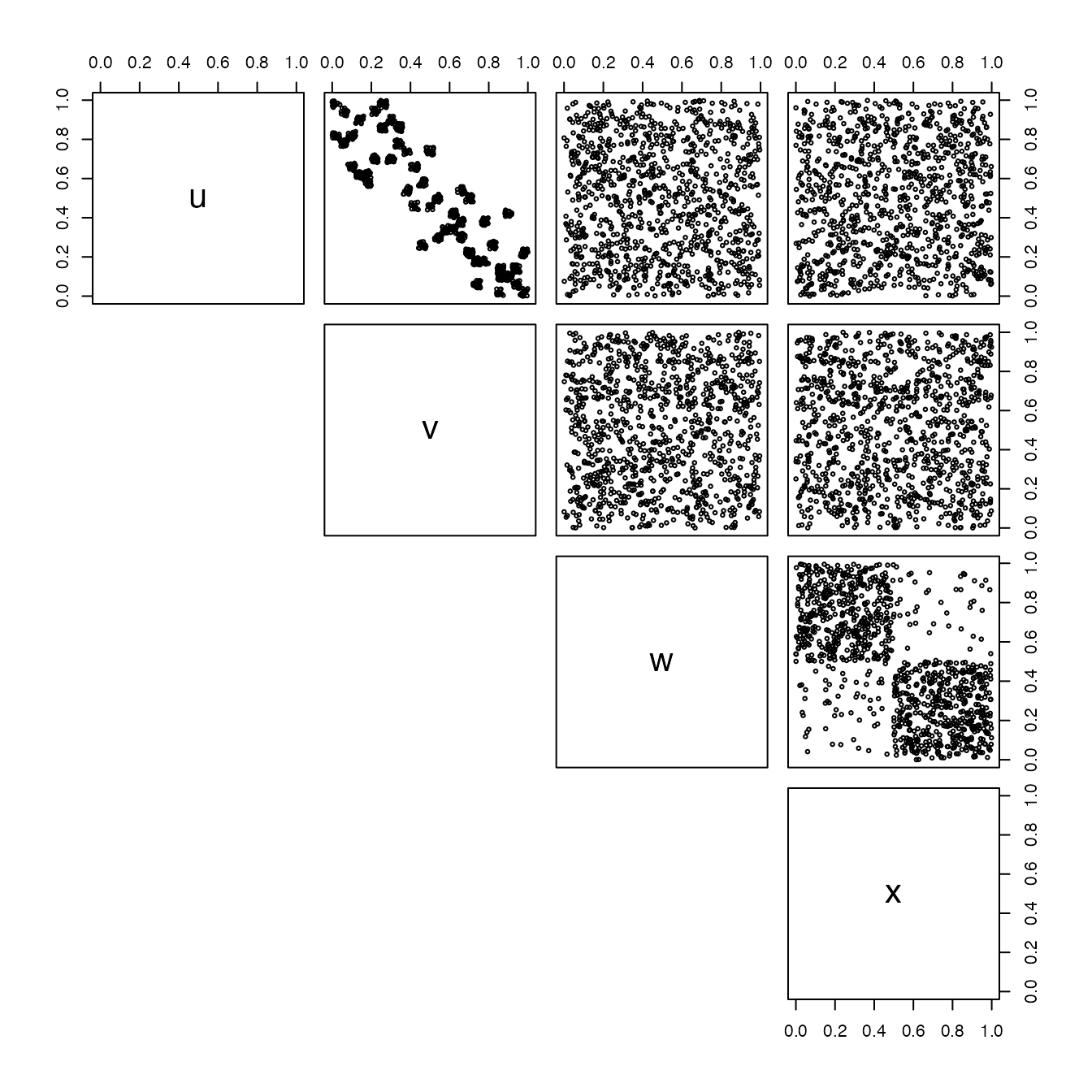
Pairs-plot of the original data with independance
cop <- cbkmCopula(x = dataset,m = 5,pseudo = TRUE,margins_numbers = c(1,2),known_cop = true_copula1)
simu <- rCopula(500,cop)
pairs(rbind(simu,dataset),col=c(rep("black",nrow(simu)),rep("red",nrow(dataset))),gap=0,lower.panel = NULL,cex=0.5)
Pairs-plot of the original data (red) and simulated data (black) – Independance case
This fit is quite good.