Copulas and Sklar Distributions
This section gives some general definitions and tools about dependence structures, multivariate random vectors and copulas. Along this journey through the mathematical theory of copulas, we link to the rest of the documentation for more specific and detailed arguments on particular points, or simply to the technical documentation of the actual implementation. The interested reader can take a look at the standard books on the subject [1–4] or more recently [5–8].
We start here by defining a few concepts about multivariate random vectors, dependence structures and copulas.
Reminder on multivariate random vectors
Consider a real valued random vector
Recall that you can construct random variables in Julia by the following code :
using Distributions
X₁ = Normal() # A standard Gaussian random variable
X₂ = Gamma(2,3) # A Gamma random variable
X₃ = Pareto(1) # A Pareto random variable with infinite variance.
X₄ = LogNormal(0,1) # A Lognormal random variableWe refer to Distributions.jl's documentation for more details on what you can do with these objects. We assume here that you are familiar with their API.
The probability distribution of the random vector
For a function
Note that the range
Copulas and Sklar's Theorem
There is a fundamental functional link between the function
A copula, usually denoted
In this documentation but more largely in the literature, the term Copula refers both to the random vector and its distribution function. Usually, the distinction is clear from context.
You may define a copula object in Julia by simply calling its constructor:
using Copulas
d = 3 # The dimension of the model
θ = 7 # Parameter
C = ClaytonCopula(d,7) # A 3-dimensional clayton copula with parameter θ = 7.ClaytonCopula{3, Float64}(θ = 7.0,)This object is a random vector, and behaves exactly as you would expect a random vector from Distributions.jl to behave: you may sample it with rand(C,100), compute its pdf or cdf with pdf(C,x) and cdf(C,x), etc:
u = rand(C,10)3×10 Matrix{Float64}:
0.53533 0.871415 0.0830739 0.873873 … 0.260401 0.677877 0.293813
0.697874 0.956939 0.0543091 0.962182 0.457821 0.614129 0.319101
0.624046 0.985113 0.0788233 0.831517 0.2417 0.797301 0.328566cdf(C,u)10-element Vector{Float64}:
0.5065188434128305
0.8510596303913105
0.05340470426052685
0.7834920439773985
0.19792913122635852
0.17627565276460402
0.20360611698855557
0.22590678606374318
0.5744595693790031
0.2657748670291536You can also plot it:
using Plots
plot(C, :logpdf)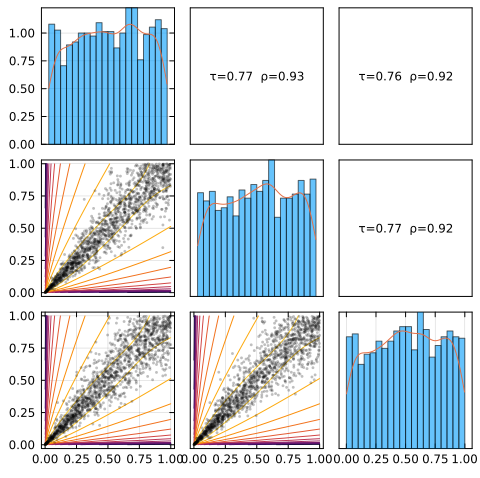
See the visualizations page for details on the visualisations tools. It’s often useful to get an intuition by looking at scatter plots.
To give another example, the function
is a copula, corresponding to independent random vectors.
This copula can be constructed using the IndependentCopula(d) syntax as follows:
Π = IndependentCopula(d) # A 4-variate independence structure.One of the reasons that makes copulas so useful is the bijective map from the Sklar Theorem [9]:
For every random vector
The copula
This result allows to decompose the distribution of
We can then leverage the Sklar theorem to construct multivariate random vectors from a copula-marginals specification. The implementation we have of this theorem allows building multivariate distributions by specifying separately their marginals and dependence structures as follows:
X₁, X₂, X₃ = Gamma(2,3), Pareto(), LogNormal(0,1) # Marginals
D = SklarDist(C, (X₁,X₂,X₃)) # The final distribution, using the previous copula C.
plot(D, scale=:sklar)The obtained multivariate random vector object are genuine multivariate random vector following the Distributions.jl API. They can be sampled (rand()), and their probability density function and distribution function can be evaluated (respectively pdf and cdf), etc:
x = rand(D,10)
p = pdf(D, x)
l = logpdf(D, x)
c = pdf(D, x)
[x' p l c]10×6 Matrix{Float64}:
5.61558 2.38963 1.33992 0.0496555 -3.00265 0.0496555
1.32695 1.06451 0.202322 17.9295 2.88645 17.9295
4.58482 1.79552 0.87742 0.293899 -1.22452 0.293899
3.54136 1.44928 0.659521 1.02256 0.0223098 1.02256
8.19215 2.60193 2.15746 0.00422491 -5.46676 0.00422491
2.70807 1.37564 0.753334 0.110682 -2.20109 0.110682
1.421 1.09743 0.293572 8.96586 2.19342 8.96586
2.32269 1.21136 0.410889 5.77309 1.75321 5.77309
12.8214 35.7519 2.76809 1.60241e-5 -11.0414 1.60241e-5
4.71009 1.91696 1.27421 0.0635668 -2.75566 0.0635668Sklar's theorem can be used the other way around (from the marginal space to the unit hypercube): this is, for example, what the pseudo() function does, computing ranks.
Distributions.jl provides the product_distribution function to create independent random vectors with given marginals. product_distribution(args...) is essentially equivalent to SklarDist(IndependentCopula(d), args), but our approach generalizes to other dependence structures.
Copulas are bounded functions with values in [0,1] since they correspond to probabilities. But their range can be bounded more precisely, and [10] gives us:
For all
where
The function MCopula(d) and WCopula(2).
The upper Fréchet-Hoeffding bound corresponds to the case of comonotone random vector: a random vector
Here is a plot of the independence, a positive dependence (Clayton), and the Fréchet bounds in bivariate cases. You can visualize the strong alignment for M and the anti-diagonal pattern for W.
p1 = plot(IndependentCopula(2), title="IndependentCopula(2)")
p2 = plot(ClaytonCopula(2, 3.0), title="ClaytonCopula(2, 3.0)")
p3 = plot(MCopula(2), title="MCopula(2)")
p4 = plot(WCopula(2), title="WCopula(2)")
plot(p1,p2,p3,p4; layout=(2,2), size=(800,600))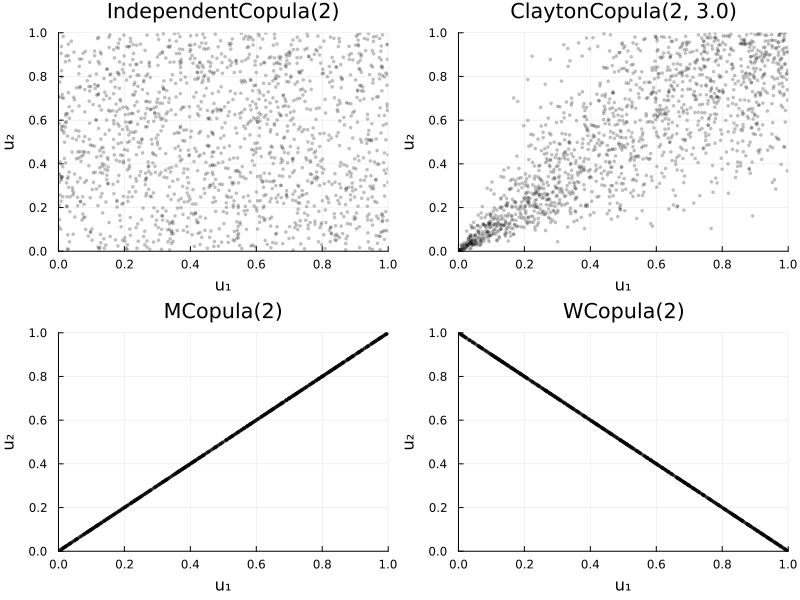
Since copulas are distribution functions, like distribution functions of real-valued random variables and random vectors, there exists classical and useful parametric families of copulas (we already saw the Clayton family). You can browse the available families in this package in the Bestiary. Like any families of random variables or random vectors, copulas are fittable on empirical data.
A tour of the main API
The public API of Copulas.jl is quite small and easy to expose on a simple example, which is what we will do right now.
Copulas and SklarDist
The most important objects of the package are of course copulas as sklar distributions. Both of these objects follow the Distributions.jl's API, and so you can construct, sample, and evaluate copulas as standard Distributions.jl objects:
using Copulas, Distributions, Random, StatsBase
C = ClaytonCopula(3, 2.0)
u = rand(C, 5)
Distributions.loglikelihood(C, u)10.09296143929457X₁, X₂, X₃ = Gamma(2,3), Beta(1,5), LogNormal(0,1)
C2 = GumbelCopula(3, 1.7)
D = SklarDist(C2, (X₁, X₂, X₃))
rand(D, 3)
pdf(D, rand(3))0.2845258952882538Basic dependence metrics.
Basic dependence summaries available on copulas, whatever their dimension d:
multivariate_stats = (
kendall_tau = Copulas.τ(C),
spearm_rho = Copulas.ρ(C),
blomqvist_beta = Copulas.β(C),
gini_gamma = Copulas.γ(C),
entropy_iota = Copulas.ι(C),
lower_tail_dep = Copulas.λₗ(C),
upper_tail_dep = Copulas.λᵤ(C)
)(kendall_tau = 0.5, spearm_rho = 0.6822338340468779, blomqvist_beta = 0.19419223902606517, gini_gamma = 0.5221285368856695, entropy_iota = -1.002086022226399, lower_tail_dep = 0.5773502691896257, upper_tail_dep = 0.0)The same functions have dispatches for u::Abstractmatrix of size (d,d) where d is the dimension of the copula and n is the number of observations, which provide sample versions of the same quantities. Moreover, since most of these statistics are more common in bivariate case, we provide the folllowing bindings for pairwise matrices of the same dependence metrics:
StatsBase.corkendall(C)
StatsBase.corspearman(C)
Copulas.corblomqvist(C)
Copulas.corgini(C)
Copulas.corentropy(C)
Copulas.corlowertail(C)
Copulas.coruppertail(C)3×3 Matrix{Float64}:
1.0 0.0 0.0
0.0 1.0 0.0
0.0 0.0 1.0and of course once again the same functions dispatch on u::Abstractmatrix, but, for historical reasons, they require dataset to be (n,d)-shaped and not (d,n), so you have to transpose.
Measure function
A measure function gives the measure of hypercubes from any copula as follows:
Copulas.measure(C, (0.1,0.2,0.3), (0.9,0.8,0.7))0.27586746224441333Subsetting (working with a subset of dimensions)
Extract lower-dimensional dependence without materializing new data:
S23 = subsetdims(C2, (2,3)) # a bivariate copula view
StatsBase.corkendall(S23)2×2 Matrix{Float64}:
1.0 0.411765
0.411765 1.0For Sklar distributions, subsetting returns a smaller joint distribution:
D13 = subsetdims(D, (1,3))
rand(D13, 2)2×2 Matrix{Float64}:
0.590621 2.8264
0.333983 1.27643Conditioning (conditional marginals and joint conditionals)
On the uniform scale (copula): distortions and conditional copulas are provided:
Dj = condition(C2, 2, 0.3) # Distributions of (U₁, U₃) | U₂ = 0.3 (d=2)
Distributions.cdf(Dj, [0.95,0.80])0.9345033795239115On the original scale (Sklar distribution):
Dc = condition(D, (2,3), (0.3, 0.2))
rand(Dc, 2)2-element Vector{Float64}:
4.015490862036963
6.306820893609225And rosenblatt transfromations of the copula (or sklardist) can be obtained as follows:
u = rand(D, 10)
s = rosenblatt(D, u)
u2 = inverse_rosenblatt(D, s)
maximum(abs, u2 .- u) # should be approx zero.2.5757174171303632e-14These transformation leverage the conditioning mechanismes.
Fitting (copulas and Sklar distributions)
You can fit copulas from pseudo-observations U, and Sklar distributions from raw data X. Available methods vary by family; see the fitting manual for details.
X = rand(D, 500)
M = fit(CopulaModel, SklarDist{GumbelCopula, Tuple{Gamma,Beta,LogNormal}}, X; copula_method=:mle)────────────────────────────────────────────────────────────────────────────────
[ CopulaModel: SklarDist ] (Copula=Archimedean d=3, Margins=(Gamma, Beta, LogNormal))
────────────────────────────────────────────────────────────────────────────────
Copula: Archimedean d=3
Margins: (Gamma, Beta, LogNormal)
Methods: copula=mle, sklar=ifm
Number of observations: 500
────────────────────────────────────────────────────────────────────────────────
[ Fit metrics ]
────────────────────────────────────────────────────────────────────────────────
Null Loglikelihood: -1643.5125
Loglikelihood: -1387.9303
LR (vs indep.): 511.16 ~ χ²(1) ⇒ p = <1e-16
AIC: 2777.861
BIC: 2782.075
Converged: true
Iterations: 27
Elapsed: 0.052s
────────────────────────────────────────────────────────────────────────────────
[ Dependence metrics ]
────────────────────────────────────────────────────────────────────────────────
Kendall τ: 0.3833
Spearman ρ: 0.5415
Blomqvist β: 0.1009
Gini γ: 0.3970
Upper λᵤ: 0.3688
Lower λₗ: 0.0000
Entropy ι: -0.5298
────────────────────────────────────────────────────────────────────────────────
[ Copula parameters ] (vcov=hessian)
────────────────────────────────────────────────────────────────────────────────
Parameter Estimate Std.Err z-value p-val 95% Lo 95% Hi
θ 1.6214 0.0400 40.519 <1e-16 1.5430 1.6999
────────────────────────────────────────────────────────────────────────────────
[ Marginals ]
────────────────────────────────────────────────────────────────────────────────
Margin Dist Param Estimate Std.Err 95% CI
#1 Gamma α 1.9931 0.1170 [1.7637, 2.2225]
θ 2.9655 0.1979 [2.5777, 3.3533]
#2 Beta α 1.0857 0.0610 [0.9661, 1.2054]
β 5.3584 0.3595 [4.6539, 6.0630]
#3 LogNormal μ 0.0746 0.0420 [-0.0077, 0.1568]
σ 0.9387 0.0297 [0.8804, 0.9969]A shortcut allows to directly get the fitting object (copula or sklardist) by simply ommiting the first CopulaModel argument:
U = pseudos(X)
Ĉ = fit(GumbelCopula, U; method=:itau)
Copulas.τ(Ĉ)0.3790252647592411Notes:
fitchooses a reasonable default per-family; passmethod/copula_methodto control it.Common copula methods include
:mle,:itau,:irho,:ibeta; for Sklar fitting,:ifm(parametric CDFs) and:ecdf(pseudo-observations) are available.CopulaModelimplements model stats:nobs,coef,vcov,stderror,confint,aic/bic,nullloglikelihood, and more.For a Bayesian workflow over Sklar models, see the examples section.
The Distributions.jl documentation states:
The fit function will choose a reasonable way to fit the distribution, which, in most cases, is maximum likelihood estimation.
We embrace this philosophy: from one copula family to another, the default fitting method may differ. Treat fit as a quick starting point; when you need control, specify method/copula_method explicitly.
Next steps
The documentation of this package aims to combine theoretical information and references to the literature with practical guidance related to our specific implementation. It can be read as a lecture, or used to find the specific feature you need through the search function. We hope you find it useful.
The package contains many copula families. Classifying them is essentially impossible, since the class is infinite-dimensional, but the package proposes a few standard classes: elliptical, archimedean, extreme value, empirical...
Each of these classes more or less corresponds to an abstract type in our type hierarchy, and to a section of this documentation. Do not hesitate to explore the bestiary !
References
H. Joe. Multivariate Models and Multivariate Dependence Concepts (CRC press, 1997).
U. Cherubini, E. Luciano and W. Vecchiato. Copula Methods in Finance (John Wiley & Sons, 2004).
R. B. Nelsen. An Introduction to Copulas. 2nd ed Edition, Springer Series in Statistics (Springer, New York, 2006).
H. Joe. Dependence Modeling with Copulas (CRC press, 2014).
J.-F. Mai, M. Scherer and C. Czado. Simulating Copulas: Stochastic Models, Sampling Algorithms, and Applications. 2nd edition Edition, Vol. 6 of Series in Quantitative Finance (World Scientific, New Jersey, 2017).
F. Durante and C. Sempi. Principles of Copula Theory (Chapman and Hall/CRC, 2015).
C. Czado. Analyzing Dependent Data with Vine Copulas: A Practical Guide With R. Vol. 222 of Lecture Notes in Statistics (Springer International Publishing, Cham, 2019).
J. Größer and O. Okhrin. Copulae: An Overview and Recent Developments. WIREs Computational Statistics (2021).
A. Sklar. Fonctions de Repartition à n Dimension et Leurs Marges. Université Paris 8, 1–3 (1959).
T. Lux and A. Papapantoleon. Improved Fréchet-Hoeffding Bounds on
-Copulas and Applications in Model-Free Finance, arXiv:1602.08894 [math, q-fin] (2017). R. Kaas, J. Dhaene, D. Vyncke, M. J. Goovaerts and M. Denuit. A Simple Geometric Proof That Comonotonic Risks Have the Convex-Largest Sum. ASTIN Bulletin: The Journal of the IAA 32, 71–80 (2002).
L. Hua and H. Joe. Multivariate Dependence Modeling Based on Comonotonic Factors. Journal of Multivariate Analysis 155, 317–333 (2017).